VoixAI: Engineering a Reliable Voice Agent for Complex Orders
A backend-first case study on building a real-time voice ordering system with multi-runtime orchestration, deterministic order state, a two-layer conversation FSM, frustration-aware escalation, and 193+ scenario reliability testing.
GitHub Repository → VoixAI repository link
“Can I get a 10-piece boneless combo, half hot and half lemon pepper, with fries?”
“Actually, make that bone-in.”
“Wait, make it 20.”
“And no fries. Veggie sticks.”
“Also, can you make half of it garlic parmesan?”
This is where the project became interesting for me.
At first, I thought building a restaurant voice agent was mainly a voice problem. The system needed to hear the customer, understand what they wanted, and respond naturally enough that the experience did not feel like a frustrating phone tree.
That part was exciting.
With modern speech models, I could connect a microphone to an agent, give it a menu, and get it to hold a surprisingly natural conversation. It could greet a customer, answer basic questions, recommend items, and even take a simple order.
But then I started thinking about the conversation above.
The customer has not placed five separate orders. They have made four corrections to the same order, in a few seconds, while expecting the system to keep up naturally.
That is not only a voice problem.
It is a backend problem.
It is a state-management problem.
It is a reliability problem.
And that is why I built VoixAI.
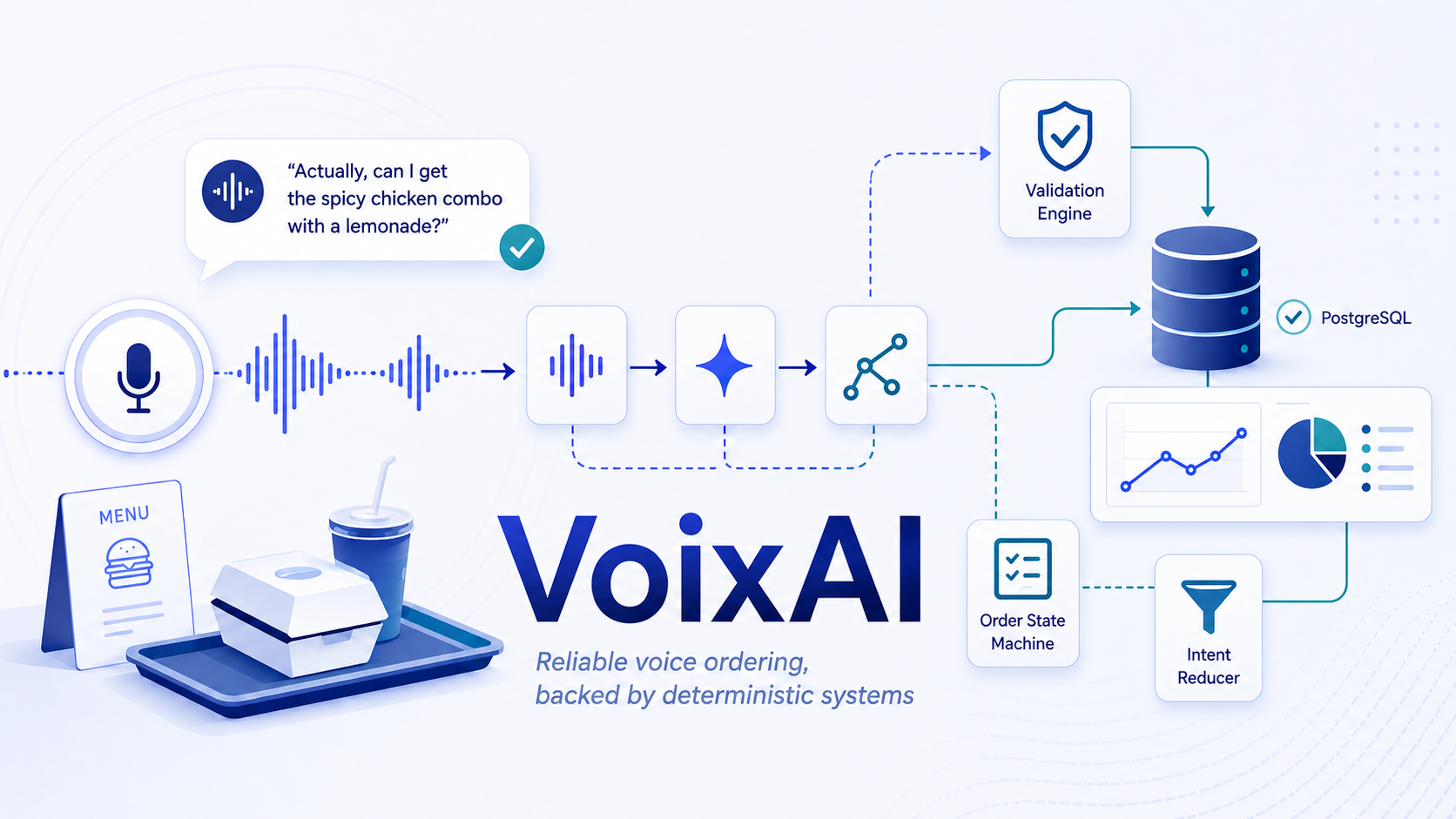
VoixAI is a real-time voice ordering system built around a Wingstop-style restaurant workflow. I intentionally chose a difficult menu because I did not want to hide behind a simple “burger and fries” demo. The catalog includes wing types, flavors, split flavors, combos, group packs, sides, dips, preparation preferences, quantity rules, and many opportunities for a customer to change their mind.
I wanted to understand what it would actually take to build a voice agent that a business could eventually trust with a real transaction.
See a messy order resolve in real time
Before getting into the architecture, this is the behavior I wanted to make reliable: a customer can speak naturally, interrupt, correct an order, and change their mind without the system losing the transaction state underneath the conversation.
Live demo: a natural ordering conversation moves through transcript capture, intent interpretation, menu and modifier validation, deterministic order updates, repricing, and final confirmation.
Demo environment note: This recording uses the VoixAI demo restaurant and a Wingstop-style ordering domain. VoixAI is not affiliated with or deployed by Wingstop.
The first version could take an order. It just did not feel human.
The first version of VoixAI was built around a structured state machine.
The flow was simple:
Greeting
↓
Collect item
↓
Collect required options
↓
Validate order
↓
Confirm cart
↓
Submit or hand off
This approach was useful because it was predictable.
The system could make sure it asked for every required option:
- Bone-in or boneless
- Flavor
- Quantity
- Side
- Dip
- Cooking preference
- Confirmation before placing the order
From a backend perspective, this was a good starting point. It made the order flow explicit and controlled.
But when I listened to the actual interaction, it felt robotic.
People do not speak in perfectly clean steps. They interrupt. They change their mind halfway through a sentence. They say “yeah” just to acknowledge something. They ask what comes with a combo before answering the original question. They may correct something the moment the agent starts repeating it back.
The state machine was good at guiding an order.
It was not good at handling the way people naturally speak.
That pushed me to explore a different question:
How can I make the conversation flexible without letting the order become unreliable?
The boundary I needed: the model can talk, but it cannot own the order
This became the main principle behind VoixAI:
Let the model handle the conversation. Let deterministic systems own the order.
An AI model is useful for understanding language.
It can understand that these phrases are all related:
- “Make it bone-in.”
- “Actually, I want traditional wings.”
- “Not boneless—the regular wings.”
- “Can you switch those to classic?”
But the model should not decide whether that update is valid.
It should not decide whether the selected item supports the requested change, whether the customer is changing the correct line item, whether the cart price changed, or whether the order is complete enough to submit.
Those decisions belong in the backend.
So I designed the agent to ask for structured actions instead of directly editing the cart.
add_item_to_order(...)
update_item_modifier(...)
replace_item(...)
remove_item(...)
validate_cart(...)
submit_order(...)
The customer speaks naturally.
The voice runtime interprets the intent.
The backend validates the request against the menu, pricing rules, and current order state.
Only then does the agent confirm the change.
Customer speaks
↓
Voice runtime identifies intent
↓
Structured tool call
↓
Ordering engine validates request
↓
Cart is updated and persisted
↓
Agent receives confirmed result
↓
Natural spoken response
This sounds like a subtle distinction, but it changes the entire system.
The model can be flexible.
The order cannot be.
Why I chose a Wingstop-style ordering flow
A simple restaurant chatbot can look impressive without dealing with the difficult parts.
A Wingstop-style order does not let the system hide.
| Customer says | What the backend has to understand |
|---|---|
| “I want a 10-piece combo.” | Wing type, flavor, side, drink, quantity, price |
| “Make it half hot and half lemon pepper.” | Flavor limits and item-specific rules |
| “Actually, make it bone-in.” | Safe replacement of the correct item |
| “Remove the fries and add veggie sticks.” | Required modifier rules and price updates |
| “Make those well done.” | Whether preparation is supported |
| “I meant 20 wings, not 10.” | Quantity replacement without duplicate items |
To the customer, this is one conversation.
To the backend, it is a sequence of state changes.
That is why I liked this use case. It forced me to think like both an AI engineer and a backend engineer.
The agent needs to understand what the customer means.
The system needs to make sure the order is still correct after every change.
I did not want to lock the product into one voice model
Once I moved beyond the initial state-machine flow, I started exploring different voice architectures.
The classic approach looks like this:
Customer Audio
↓
Speech-to-Text
↓
LLM + Tool Calls
↓
Text-to-Speech
↓
Agent Audio
This is a strong architecture for debugging and control. I can inspect the transcript, look at tool calls, understand why the model asked a question, and trace how the cart changed.
But it can sometimes feel less natural because speech gets flattened into text before the model sees it.
Then there are speech-to-speech models.
These systems can handle the rhythm of a conversation more naturally. They can be better at barge-in, backchanneling, timing, and expressive responses because the interaction remains closer to audio.
But they come with different trade-offs. They can be harder to inspect, harder to replay, and more dependent on provider behavior.
Instead of choosing one forever, I built VoixAI around multiple runtime paths:
| Runtime | Stack | Why I use it |
|---|---|---|
| Classic STT → LLM → TTS | Deepgram → OpenAI GPT-5.3 → Cartesia | Better visibility, transcripts, and tool control |
| OpenAI Realtime | gpt-realtime-2 (speech-to-speech) | Lower-friction real-time conversation |
| Gemini Live | gemini-3.1-flash-live-preview (speech-to-speech) | More audio-native turn-taking and natural interaction |
The point was not to create three versions of the same product.
The point was to make the voice layer replaceable.
If one provider improves latency, another becomes cheaper, or a real-time runtime has an outage, I do not want to rewrite the ordering system underneath it.
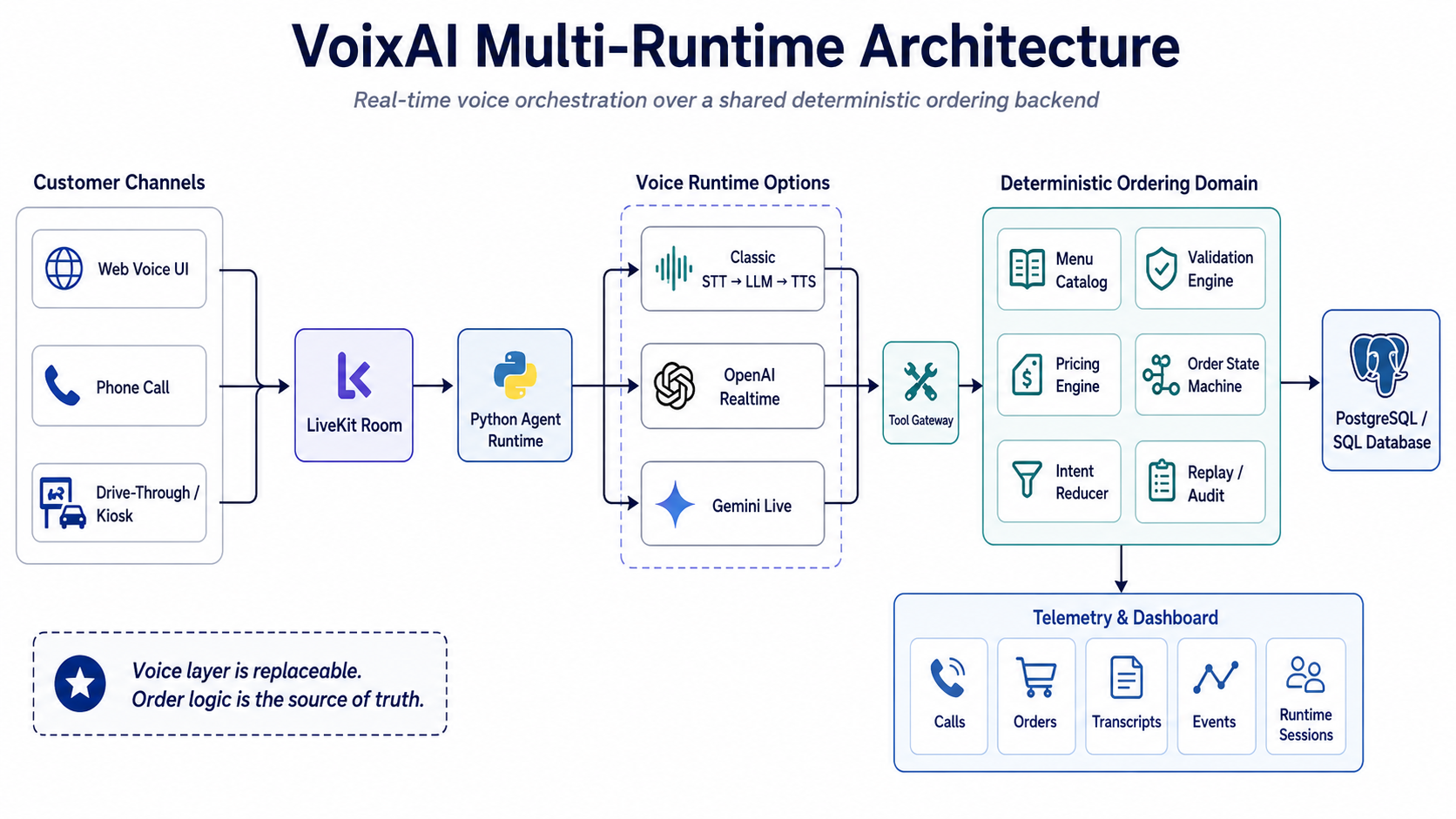
Diagram 1: The customer interacts with a LiveKit room and Python agent runtime. Classic, OpenAI Realtime, and Gemini Live paths connect to the same ordering and validation layer.
The order engine became the real center of the project
The voice agent is the part people see.
But the order engine is the part that makes VoixAI useful.
I kept the ordering domain separate from the LiveKit agent code. The core package does not depend on a specific voice provider or real-time framework.
It owns the parts of the product that should remain stable:
- Menu catalog and item templates
- Flavor and modifier validation
- Combo and group-pack rules
- Pricing, tax, and upcharges
- Order lifecycle state machine
- Confirmation checks
- Deterministic order-intent reducer
- Serialization
- Replay of saved intent sequences
That separation matters because it gives the product room to grow.
The same ordering engine can eventually support:
- Voice ordering
- Web ordering
- Mobile ordering
- A store employee dashboard
- POS integrations
- Automated regression tests
- Customer order history
The voice agent is one interface into the system.
It is not the source of truth.
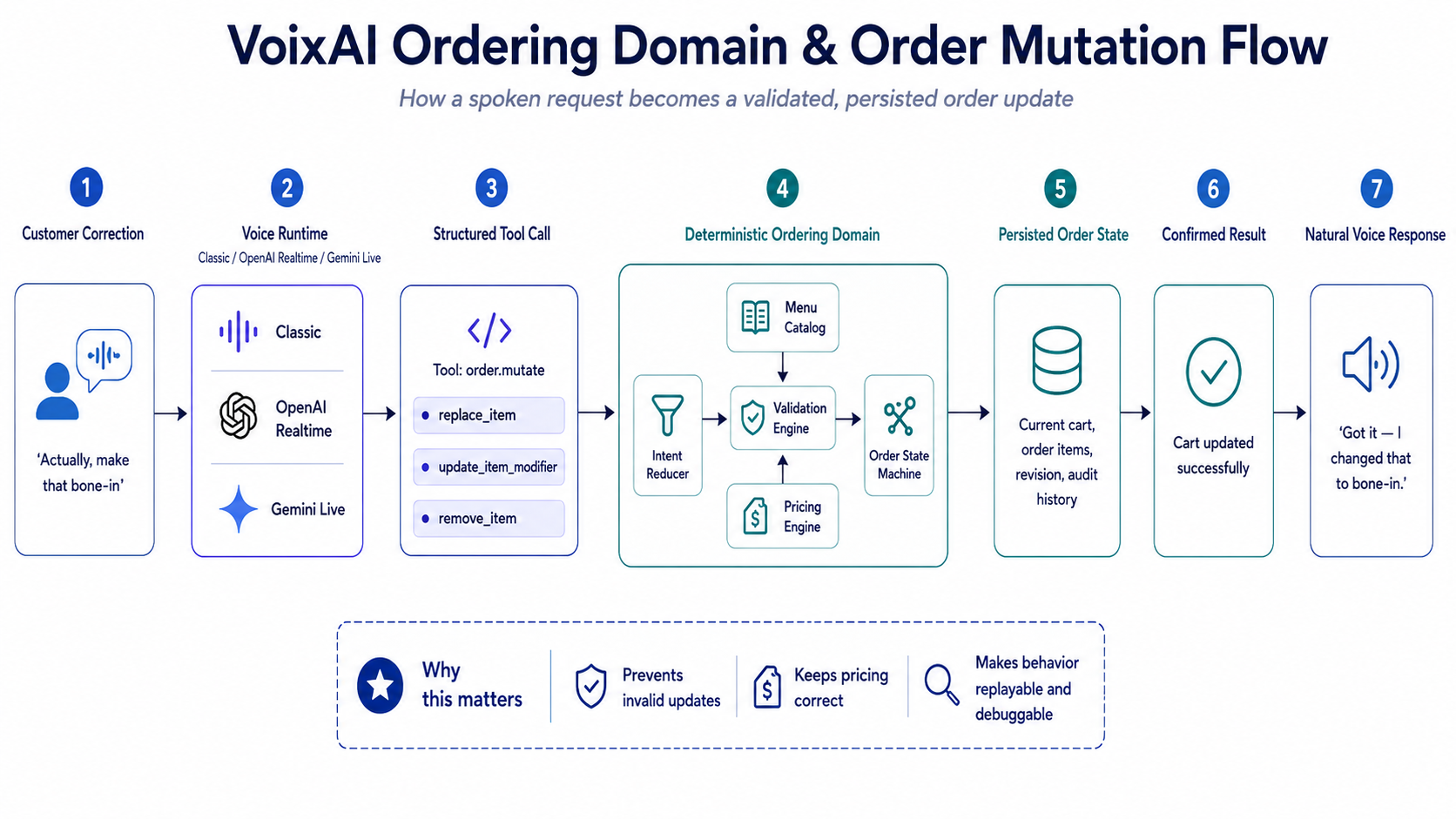
Diagram 2: The voice layer sends structured order intents. The ordering engine applies the mutation, validates it against the menu catalog, recalculates pricing, and returns a confirmed result.
Every call leaves a trail
Early versions of VoixAI were stateless. The conversation happened, the order was placed or it was not, and then it was gone.
That made debugging painful. If a test failed or a live call went wrong, I had to replay the entire scenario from memory. There was no persisted transcript, no record of which intent was routed where, no audit trail for what the frustration monitor decided.
So I added persistence.
The system now records everything through SQLAlchemy. Call records with full transcripts, per-turn persistence, analytics events (latency samples, provider errors), escalation records, orders with idempotency keys, and runtime session configs.
The API exposes endpoints for opening a call record, appending turns, recording events, and finalizing a call with duration, outcome, and sentiment estimate. An analytics overview endpoint aggregates success rate, containment, completion, revenue, average order value, and latency percentiles.
All of it is best-effort. It never blocks the live call path. If the database is unreachable, the agent keeps working. But when it is available, every call leaves enough evidence to debug, evaluate, and improve.
“Actually…” became a state-management problem
The hardest part of this project was not adding an item to the cart.
It was dealing with corrections.
A customer saying, “Actually, make that bone-in,” sounds simple.
But the system has to know:
- Which item are they changing?
- Does that item support the new wing type?
- Which modifiers should remain?
- Which modifiers are now invalid?
- Does the flavor selection still work?
- Does the price change?
- Has the customer already changed the order again?
I did not want the agent to keep the entire answer inside a long prompt.
Instead, I modeled order changes as explicit intents.
AddItem
↓
UpdateFlavor
↓
ReplaceWingType
↓
RemoveSide
↓
AddDip
↓
ValidateOrder
↓
ConfirmOrder
The reducer applies the intent, validates the resulting state, and produces the updated order.
The project also supports replaying saved intent sequences.
That gives me a much better way to debug failures.
Instead of asking, “What did the LLM think happened?” I can inspect the actual progression:
1. Added 10-piece boneless wings
2. Set flavor to Hot
3. Replaced Hot with Lemon Pepper
4. Added fries
5. Removed fries
6. Added veggie sticks
7. Confirmed order
That is easier to test, easier to replay, and much easier to reason about.
The order is not just remembered by the conversation.
It is represented as state.
A two-layer conversation architecture
The order reducer solved the data problem. But the conversation still needed structure.
A customer does not just say “add wings” and wait. They greet the agent, maybe ask about store hours, maybe want to track an existing order before placing a new one, maybe escalate to a human mid-conversation.
So I built a second layer on top of the order engine: a conversation core with its own intent router and state machine.
The intent router is deterministic. It uses grammar and keyword rules to classify transcripts into a closed set of intents: place_order, modify_order, track_order, cancel_order, store_info, speak_to_human, and smalltalk_or_unknown. No API call needed. No model hallucination risk.
The top-level state machine drives the session flow:
GREETING → IDENTIFY → ROUTE → [ORDER | TRACK | CANCEL | STORE_INFO | ESCALATE] → WRAPUP
GREETING fires on session start with a deterministic greeting. IDENTIFY resolves the caller. ROUTE sends the conversation to the right destination node.
Inside the ORDER node, a sub-FSM drives the ordering conversation itself:
SELECT_ITEM → CONFIGURE_ITEM → ADD_SIDES → ADD_DRINKS → REVIEW → CONFIRM → PLACE
This sub-FSM checks which slots are filled and which are missing for each line item. It detects mid-order cancellation. It handles corrections, “add another” requests, and affirmative or negative responses.
The important part is that both layers are testable without any audio, any API key, or any LiveKit connection. The intent router and conversation FSM are pure Python with deterministic inputs.
That made them easy to unit test, easy to replay, and easy to reason about.
A live call is not just another API request
While building the backend, I also had to think differently about latency.
A dashboard query taking three seconds is annoying.
A voice agent taking three seconds after every customer sentence feels broken.
That is why I think about VoixAI in two separate paths.
The control plane handles normal backend work:
- Creating a session
- Issuing LiveKit tokens
- Resolving store configuration
- Loading menu context
- Selecting a runtime
- Creating a draft order
- Recording session metadata
The real-time path handles the live customer interaction:
- Audio streaming
- LiveKit room participation
- Turn detection
- Barge-in handling
- Streaming responses
- Tool calls
- Runtime fallback decisions
The live path should stay focused on the customer.
Analytics, dashboards, cost aggregation, and other non-critical work should not make someone wait while placing an order.
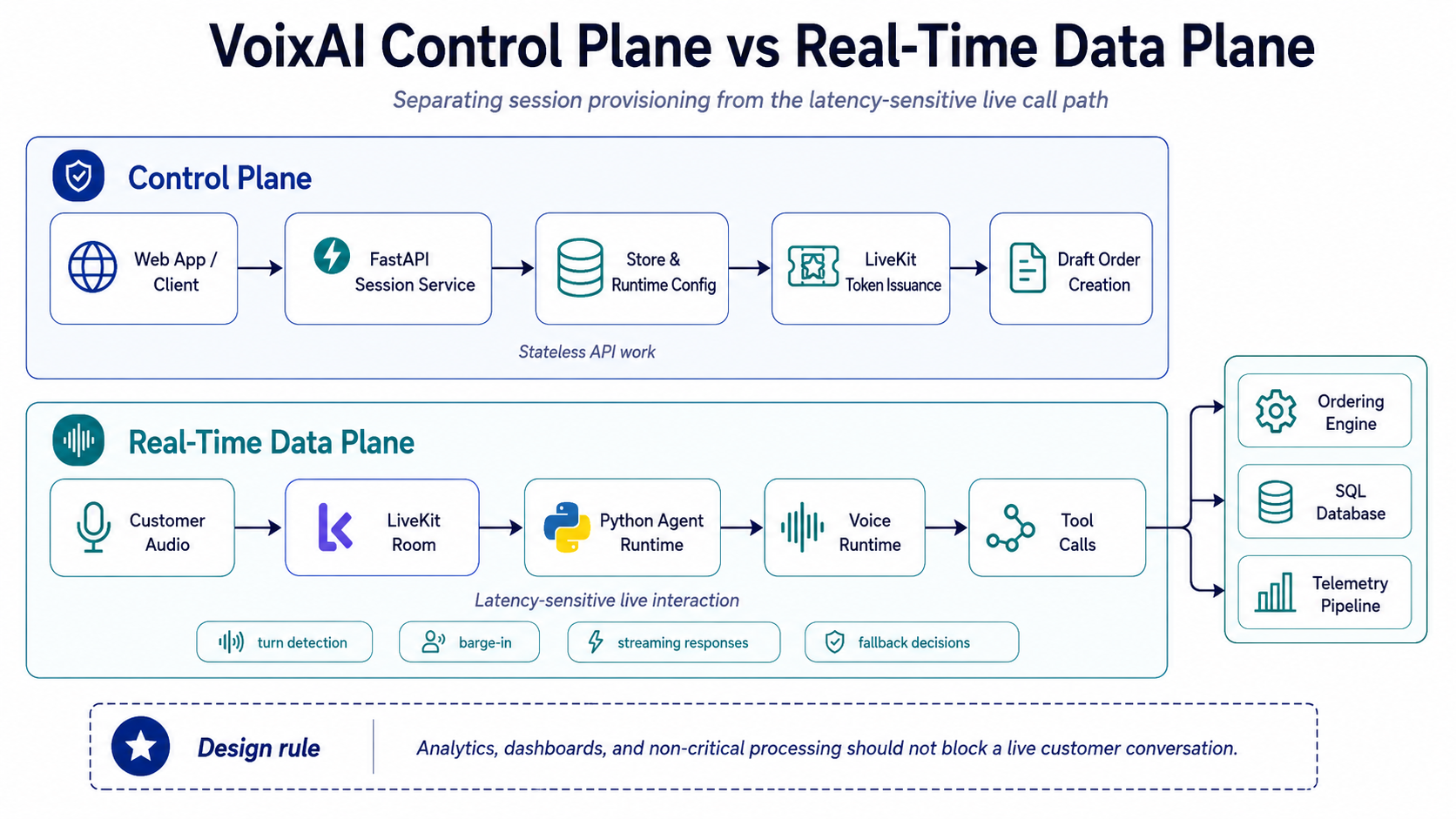
Diagram 3: The control plane creates and configures a session. The real-time path keeps the customer conversation responsive.
Thinking about scale before I need it
I am not claiming that VoixAI is already handling thousands of live restaurant calls.
It is not.
But I also did not build it as a single script that works only for one demo session.
A real deployment has to deal with:
- Multiple concurrent LiveKit rooms
- Agent-worker CPU and memory
- Voice-provider concurrency limits
- Tool-call latency
- Database load
- Telemetry volume
- Provider outages
- Call failures
- Store-level isolation
The current architecture already separates the web app, FastAPI API layer, Python agent runtime, shared ordering domain, database, and dashboard. A full Docker Compose stack orchestrates all of these: LiveKit, the API, the agent runtime, and the frontend.
That gives the system a clean path toward scaling horizontally.
The next hardening stage is straightforward:
- Run the API as stateless instances behind a load balancer.
- Use PostgreSQL as the durable production database instead of the local SQLite fallback.
- Scale agent workers based on active rooms, CPU, memory, and provider capacity.
- Keep telemetry and analytics off the real-time call path.
- Add authentication, rate limiting, and tenant isolation.
- Load-test concurrent calls before making any serious scale claims.
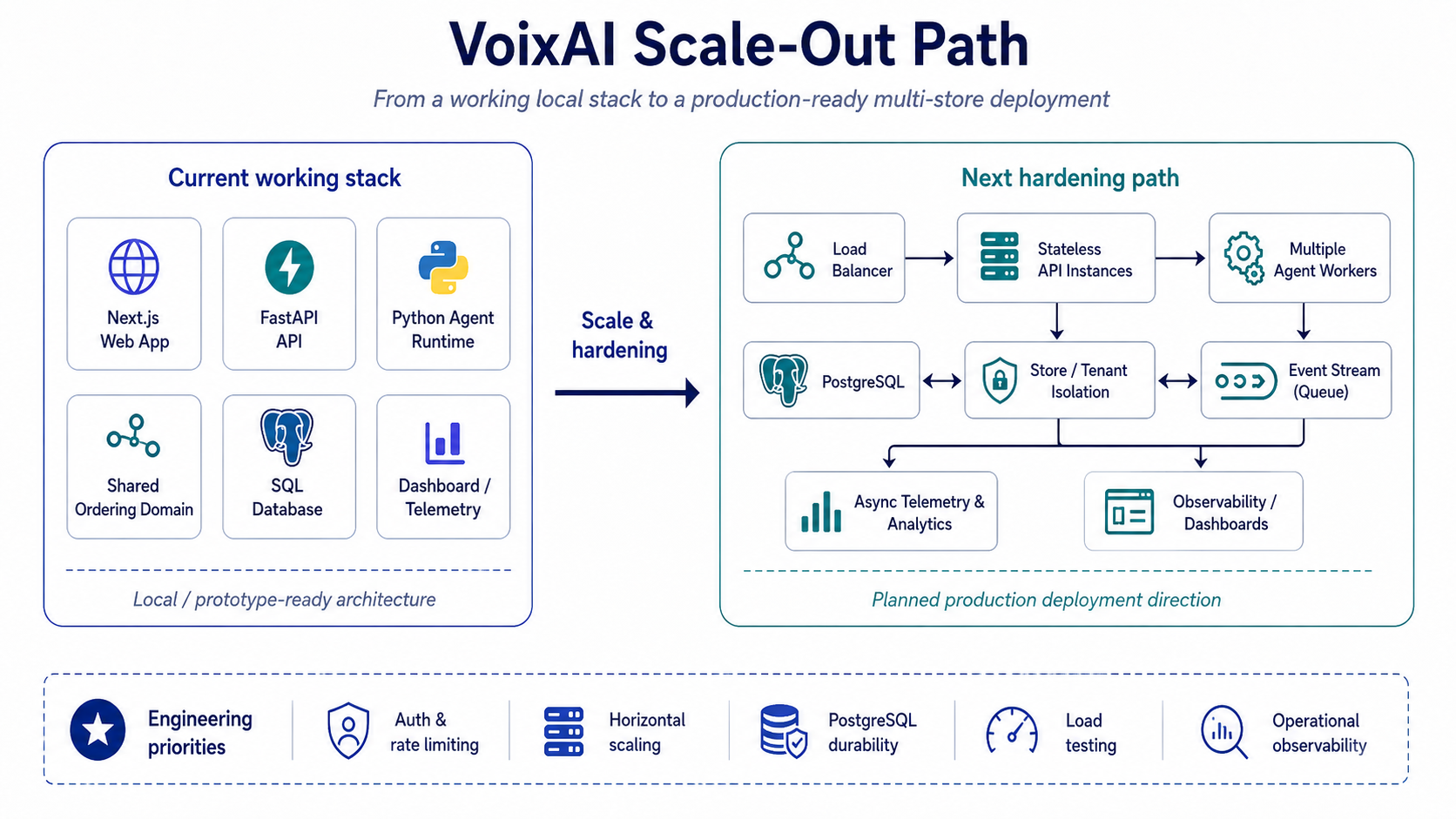
Diagram 4: The current separation between agent workers, API services, the ordering domain, and persistent storage creates a clear path toward scale. This is the deployment direction I am hardening next.
For me, that is the difference between building something that works once and building something that has a chance to work in the real world.
Two interfaces around the same live call
A voice agent is invisible. The customer hears audio and maybe sees a transcript. There is no natural way for them to see the order validation, pricing, runtime selection, or recovery logic working underneath the conversation.
That matters for two different audiences.
During a call, the customer-facing interface stays focused on the order. It presents voice state, a live transcript, the evolving order summary, clarification prompts, and confirmation feedback without exposing raw operational details.
For demos and technical inspection, the intelligence view makes the backend work visible. The runtime publishes telemetry snapshots on a LiveKit data channel, and the frontend can render the current conversation node, last routed intent, structured order state, quote status, guardrail signals, and latency data that is actually available for that voice mode.
The agent is named Mia. She greets the customer, takes the order, and handles corrections. As the conversation changes, the interface can show the order forming line by line while the backend validates menu rules, applies deterministic order mutations, and recalculates the quote.
Classic sessions can emit per-stage STT, LLM, and TTS latency metrics. Realtime sessions expose the session-level timing available from their runtime rather than pretending that the same per-stage metrics exist for every provider.
When an escalation is triggered, the customer interface can move to a clear “Call Escalated” state and close the session cleanly, while the operator-facing records preserve the conversation context and reason for handoff.
After the call: the operator console
A reliable voice agent needs more than a live conversation screen. Once a call ends, an operator needs to understand what happened, whether the order was completed, which voice runtime handled the session, where a handoff occurred, and what business outcome the interaction produced.
VoixAI keeps the customer experience separate from the operator workflow. The customer gets a fast ordering conversation; the business gets structured call records, persisted orders, and operational visibility built from the same session telemetry and backend events.
Operational overview
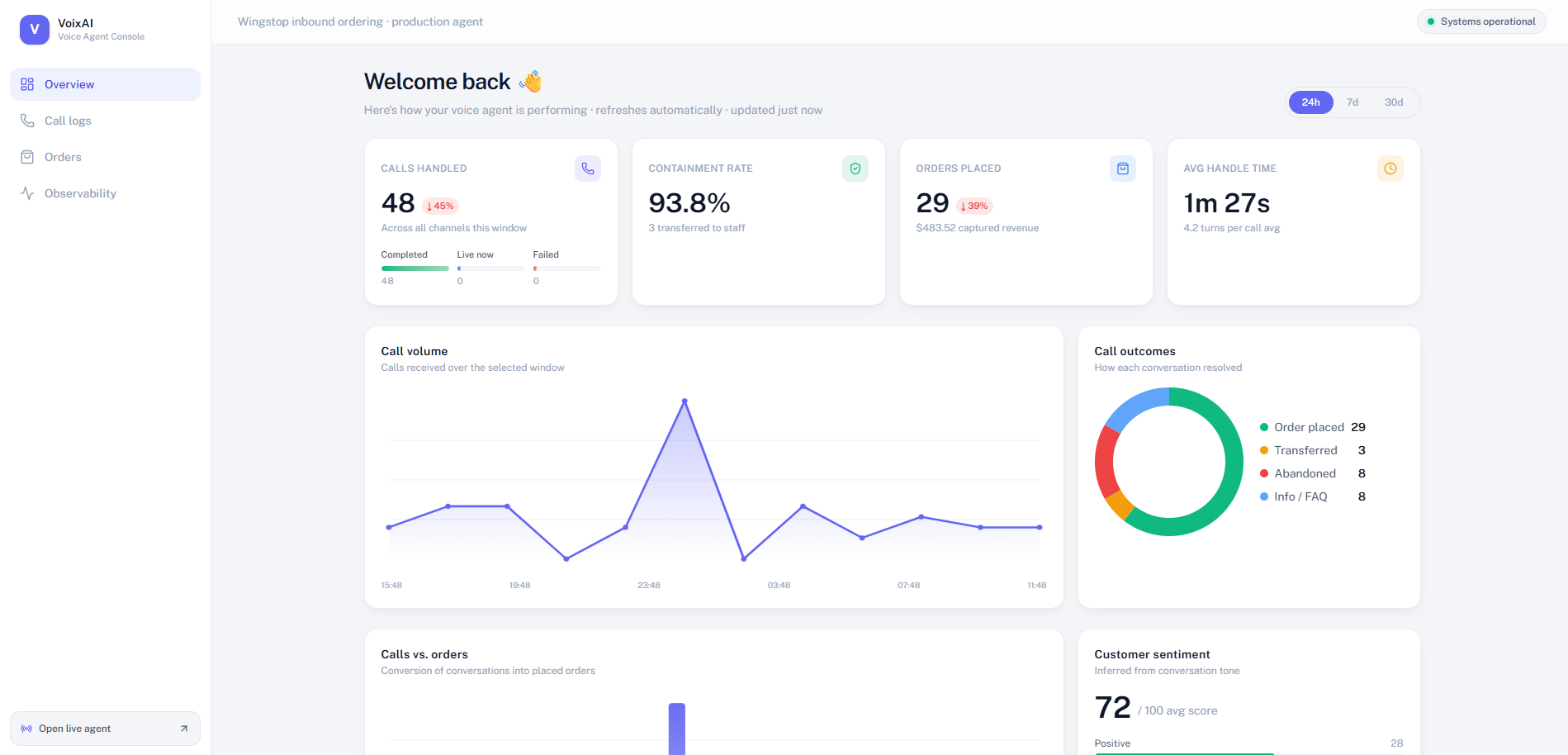
Operator overview: representative demo telemetry is aggregated into call volume, containment, placed orders, captured revenue, average handle time, conversation outcomes, conversion, and inferred customer sentiment.
Call-level traceability
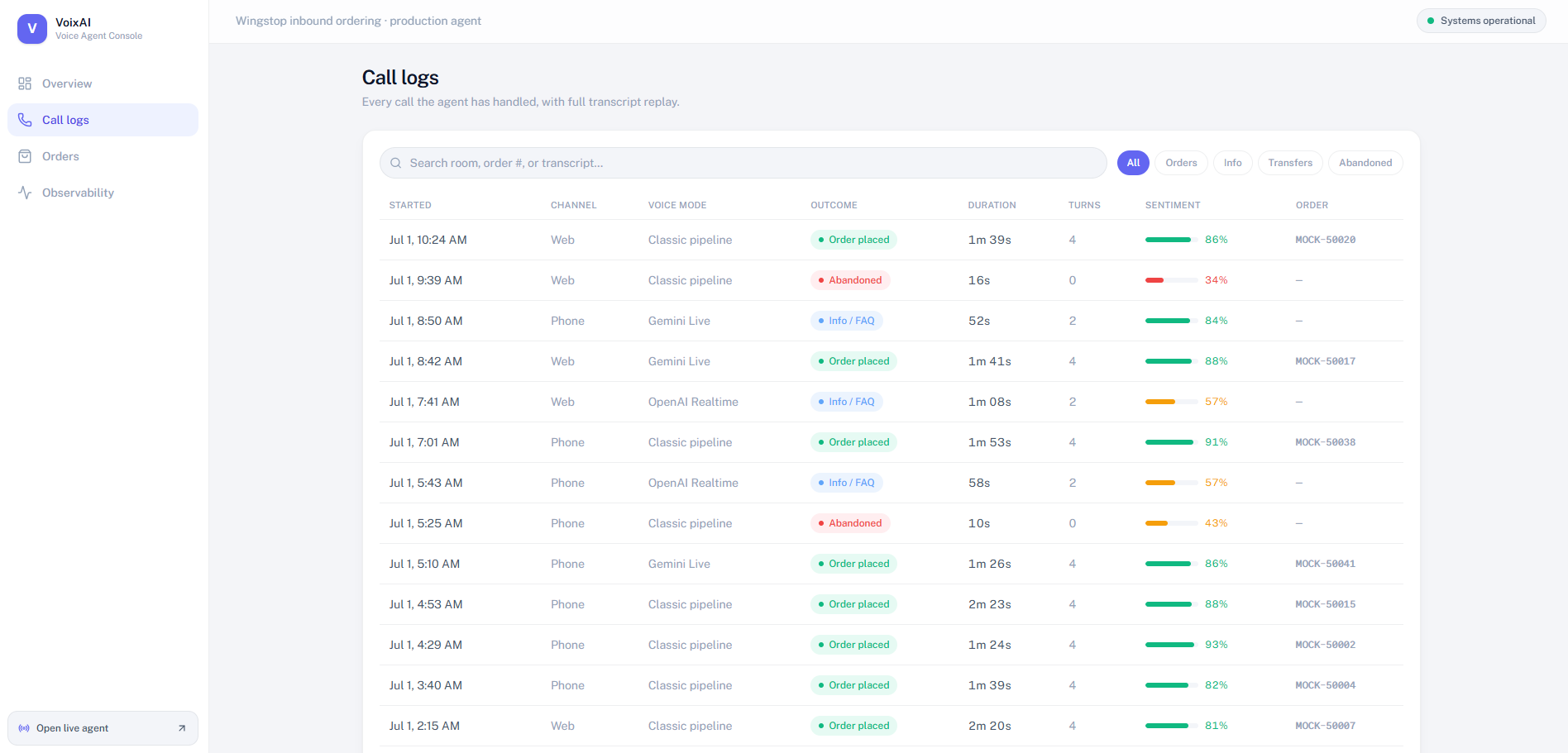
Call logs: each session can be inspected by start time, channel, selected voice runtime, outcome, duration, turn count, inferred sentiment signal, and linked order reference. This makes failures and ordering corrections replayable instead of hiding inside an LLM transcript.
Persisted order records
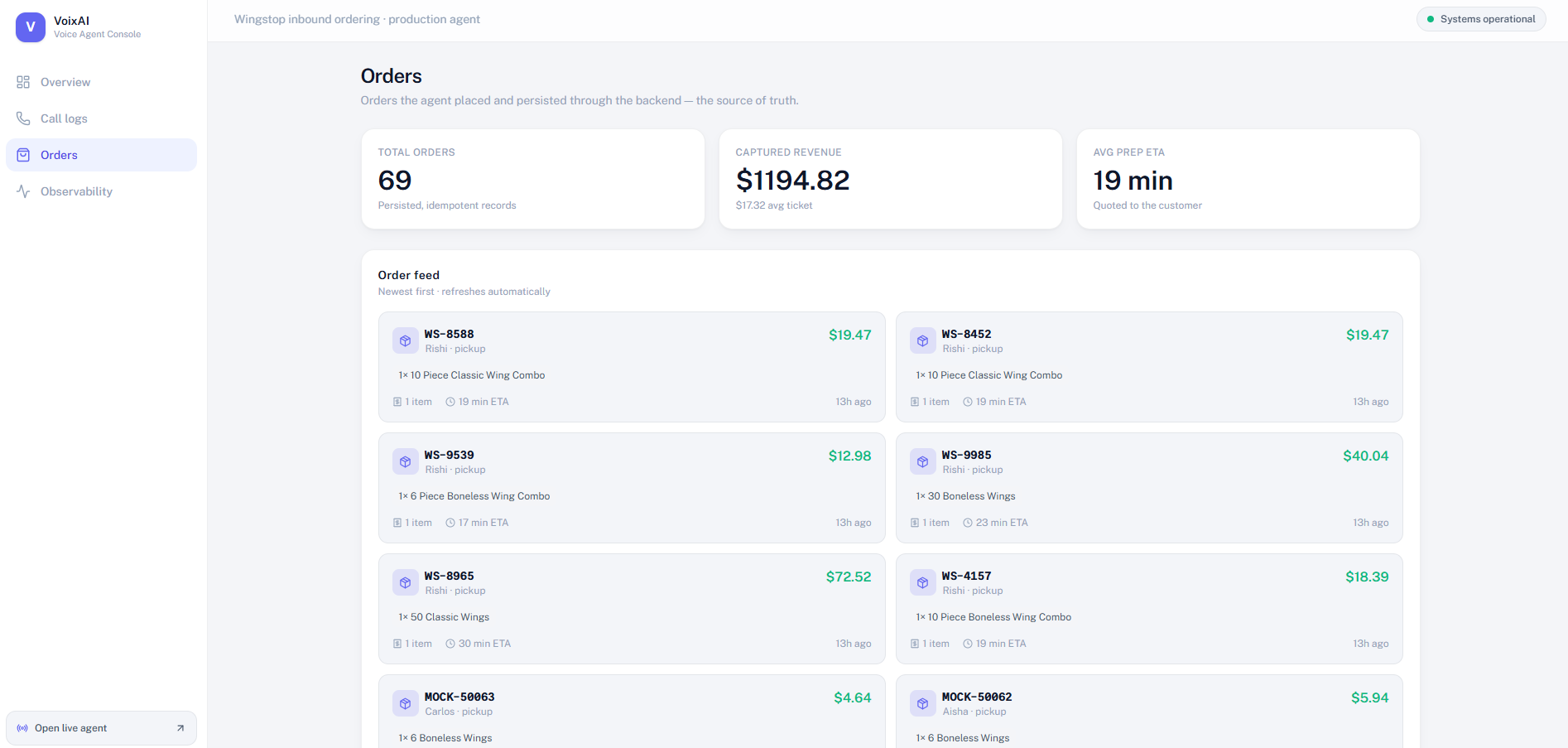
Order system of record: validated voice interactions become persisted order records with identifiers, structured line items, quoted totals, fulfillment metadata, and estimated preparation time.
Demo environment note: The operator console uses representative VoixAI demo records. Labels and order data shown here are not evidence of a live Wingstop deployment.
Reliability is not about never failing
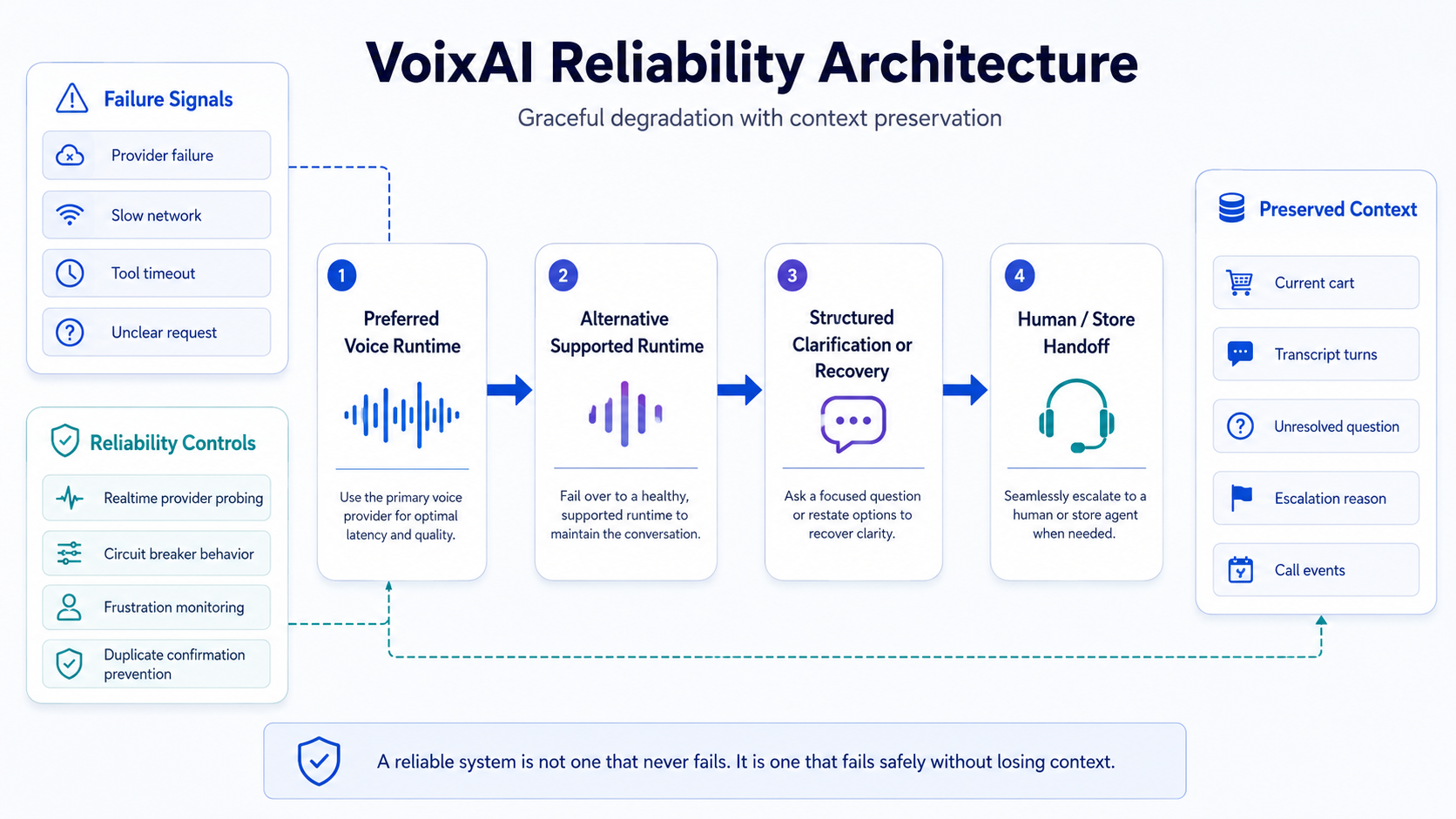
A reliable system is not a system where nothing ever goes wrong.
Providers fail. Networks slow down. Tool calls time out. Customers say unclear things. Store inventory can change.
The important question is what the system does next.
VoixAI already includes building blocks for that direction:
- Frustration monitor — deterministic scoring based on slot corrections, node loops, low-confidence streaks, negative sentiment, duration without progress, and explicit handoff requests. Returns an
EscalationDecisionwhen thresholds are crossed. - Circuit breaker — standard CLOSED/OPEN/HALF_OPEN pattern with configurable failure thresholds, recovery timeouts, and exponential backoff with jitter on retries.
- SIP handoff — wraps LiveKit’s SIP transfer API for real warm-transfer to a human. Falls back to a mock handler in demo mode.
- Realtime-provider probing — startup probe tests the realtime publisher connection and falls back to the classic pipeline on failure.
- Escalation after repeated placement failures
- Duplicate confirmation prevention
- Persisted call events, transcripts, and escalation records
The fallback path is designed around continuity:
Preferred voice runtime
↓
Alternative supported runtime
↓
Structured clarification or recovery
↓
Human/store handoff
A handoff should not make the employee restart the conversation.
The employee should receive the current cart, available transcript, unresolved question, and reason for escalation.
The AI should not become more confident when it is uncertain.
It should become safer.
How I am measuring whether it is actually getting better
A voice agent sounding natural is not enough.
I want to know whether it completes correct orders.
That is why the system persists calls, transcripts, events, runtime sessions, orders, and dashboard metrics. And that is why I built a reliability regression suite.
The suite currently contains 193+ scenarios covering happy paths, messy corrections, cancellations, invalid modifiers, ambiguous phrasing, bilingual turns, pricing and repricing, confirmation gates, and stale-state behavior. It includes generated seed cases as well as transcript-derived regressions from previously failed ordering flows.
The scenarios run fully offline. No Gemini Live. No LiveKit. No audio. No API keys. Just deterministic turn-by-turn assertions against the conversation FSM and order reducer.
Provider-delay and runtime-fallback cases are deterministic simulations of orchestration behavior. They validate state continuity, recovery decisions, and escalation rules; they do not pretend to measure live provider latency.
The evaluation scenarios are focused on situations that look more like real customer behavior:
- Changing the order multiple times
- Interrupting confirmation
- Asking ambiguous questions
- Repeating a request after a delay
- Invalid flavors or modifiers
- Simulated provider delay and recovery decisions
- Runtime fallback
- Order-placement failure
- Customer frustration
- Human escalation
The metrics I care about are practical:
| Metric | Why it matters |
|---|---|
| Validated order completion rate | Did the system finish a correct order? |
| Cart correction recovery rate | Can it handle changes safely? |
| Tool-call success rate | Is backend execution reliable? |
| Barge-in recovery latency | Does the conversation feel natural? |
| Fallback success rate | Can the system degrade safely? |
| P95 response latency | Does the customer experience stay responsive? |
| Cost per validated order | Is the system useful for a business? |
The system should improve because the numbers show it is improving.
Not because one new voice sounds better in a demo.
What I am still working on
I want to be honest about where VoixAI is today.
The main architecture is in place: the ordering engine, menu validation, pricing, three voice runtimes, conversation FSM, frustration monitor, circuit breaker, SIP handoff, telemetry, dashboard, persistence, replay support, 193+ scenario reliability suite, and a full Docker Compose stack.
But there are still important things I am hardening:
- Authentication and rate limiting for the LiveKit token endpoint
- Runtime config via local JSON files is not multi-instance safe and never garbage-collected
- Production configuration for SIP handoff
- Stronger request idempotency and order-version protection for complex concurrent updates
- Browser-level end-to-end tests
- Full ORDER/TRACK/STORE_INFO/CANCEL destination node conversation simulations
- Load testing with realistic concurrent ordering sessions
I do not see these as things to hide.
This is the part where a promising prototype turns into a reliable system.
Final thoughts
Building VoixAI changed how I think about voice AI.
The voice is only the interface. The real engineering work happens behind it:
- Real-time infrastructure
- Stateful backend design
- Menu and pricing validation
- Deterministic order mutations
- Two-layer conversation FSM
- Runtime abstraction
- Frustration-aware escalation
- Circuit-breaker resilience
- Telemetry, persistence, and replay
- 193+ scenario reliability testing
- Cost tracking
- A load-testing plan for realistic concurrent ordering sessions
AI coding tools helped me move faster with scaffolding, implementation, and refactoring. But they did not decide where the source of truth should live, how an order correction should be represented, what happens when a provider fails, or when the system should escalate instead of guessing.
Those are the decisions I wanted VoixAI to demonstrate.
VoixAI is not just a voice agent that can take an order. It is a backend-first AI system designed around a harder goal: making real-time AI interactions reliable enough to support real business workflows.
GitHub Repository → VoixAI repository link
Architecture Diagrams → VoixAI Architecture diagrams